Abstract
Reconstruct human mesh from a monocular image.
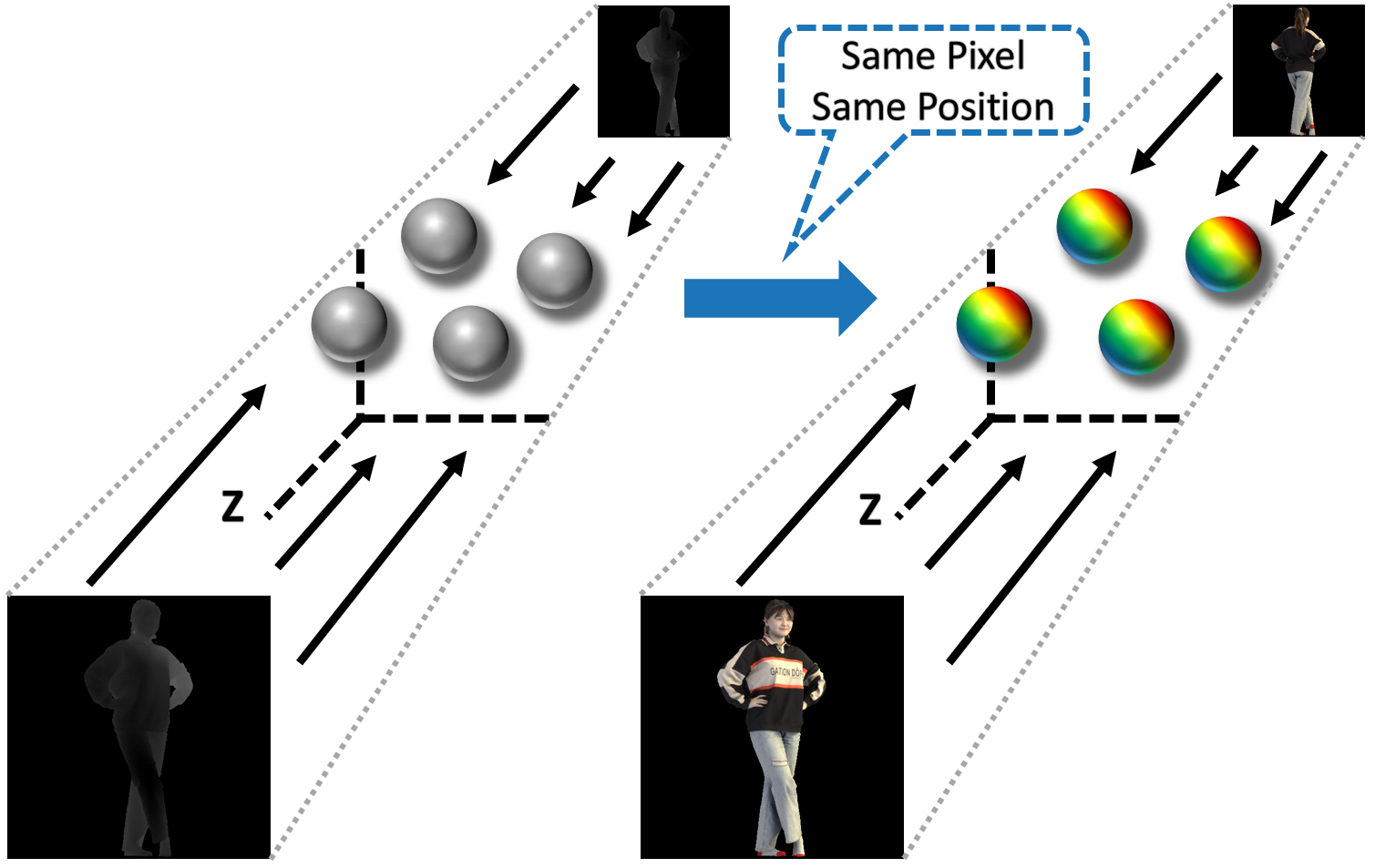
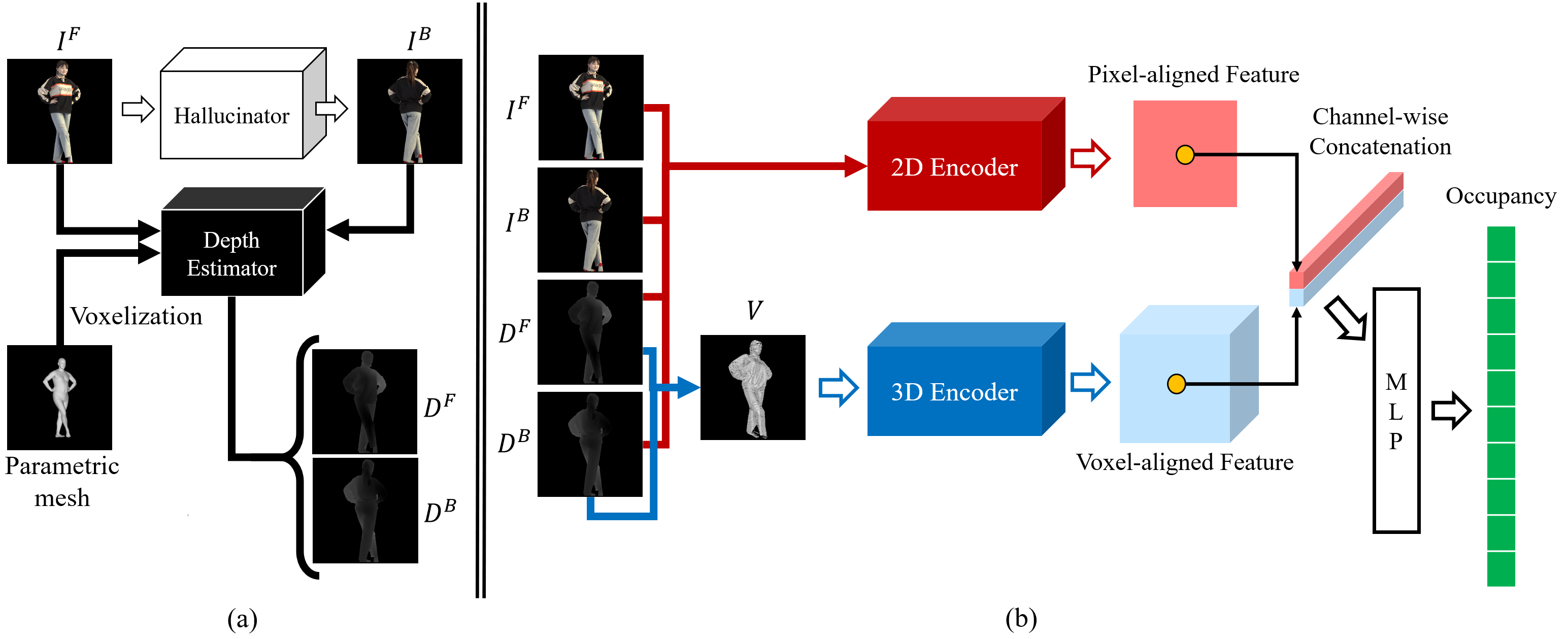
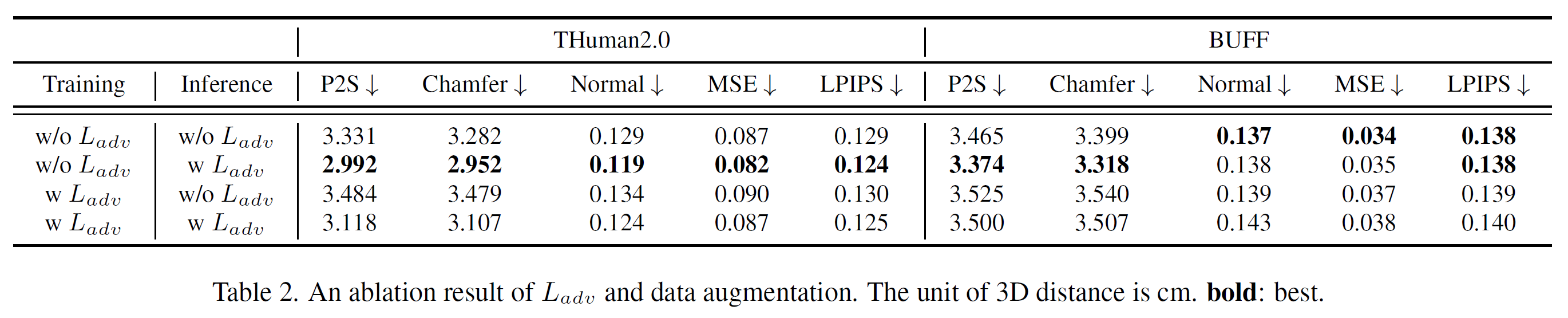
Recently, implicit function (IF)-based methods for clothed human reconstruction using a single image have received a lot of attention. Most existing methods rely on a 3D embedding branch using volume such as the skinned multi-person linear (SMPL) model, to compensate for the lack of information in a single image. Beyond the SMPL, which provides skinned parametric human 3D information, in this paper, we propose a new IF-based method, DIFu, that utilizes a projected depth prior containing textured and non-parametric human 3D information. In particular, DIFu consists of a generator, an occupancy prediction network, and a texture prediction network. The generator takes an RGB image of the human front-side as input, and hallucinates the human back-side image. After that, depth maps for front/back images are estimated and projected into 3D volume space. Finally, the occupancy prediction network extracts a pixel-aligned feature and a voxel-aligned feature through a 2D encoder and a 3D encoder, respectively, and estimates occupancy using these features. Note that voxel-aligned features are obtained from the projected depth maps, thus it can contain detailed 3D information such as hair and cloths. Also, colors of each query point are also estimated with the texture inference branch. The effectiveness of DIFu is demonstrated by comparing to recent IF-based models quantitatively and qualitatively.